




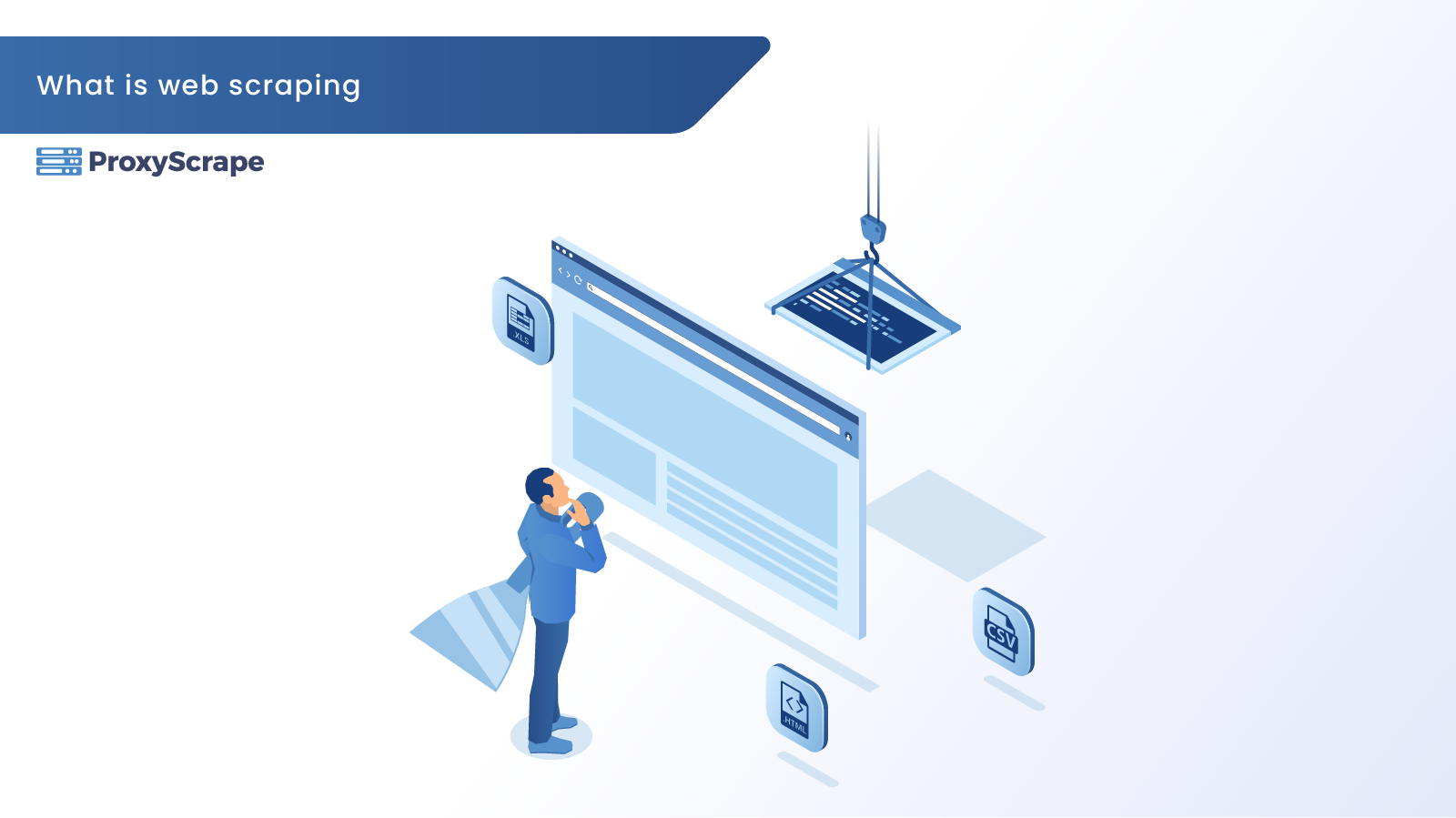
The amount of data on the internet has increased exponentially. In return, this has increased the demand for data analytics. As data analytics is very widespread, one needs to generate analytics from more than one resource. Therefore companies need to collect this data from a variety of resources. Before getting into the details of web
Author: ProxyScrape
What is an IP Scrambler
By: ProxyScrapeJun-28-2021
Your IP address provides valuable information about you to the internet, such as your location, although you may not be aware of it. When you access a web page on the internet, it will establish a connection between your device and the web server on which the web page is hosted. Plenty of information is
What are Honeypots
By: ProxyScrapeJun-28-2021
Many businesses currently depend on large quantities of data obtained across the internet through web scraping to implement business decisions. However, web scraping often confronts several challenges and, one such challenge is the honeypot traps. On the other hand, Honeypots are a vital asset to the Cybersecurity of your organization as well. So this article
What is data parsing?
By: ProxyScrapeMay-30-2021
Data Parsing is a term that you often come across when you work with large quantities of data, especially for those who scrape data from the web as well as software engineers. However, data parsing is a topic that needs to be discussed in greater depth. For instance, what exactly is data parsing, and how
What Can Someone Do With Your IP Address?
By: ProxyScrapeMay-19-2021
Every device connected to the internet has a specific address known as IP (Internet Protocol) address. The IP address is composed of a series of numbers separated by decimal points. It looks somewhat similar to “198.169.0.100.” This number is essential for communication between different devices and is also very important for exchanging data. Every device
10 Best Data Center Proxy providers
By: ProxyScrapeMay-19-2021
No one can deny the importance of a good proxy server for web data extraction, website performance testing, and other activities. There are plenty of other use cases in which proxies could be of massive help—for example, bypassing geo-restrictions or hiding identity. Proxies keep you anonymous by acting as a gateway between you and the
How to Web Scrape Amazon With Python
By: ProxyScrapeMay-19-2021
Web scraping is the art of extracting data from the internet and using it for meaningful purposes. It is also sometimes known as web data extraction or web data harvesting. For newbies, it is just the same as copying data from the internet and storing it locally. However, it is a manual process. Web scraping
Guide to Stock Market Data Scraping (Nasdaq, S&P 500, etc)
By: ProxyScrapeMay-18-2021
The stock market frequently confronts unexpected changes. However, the uncertainty of the stock market further escalated with the advent of Covid-19 and has made the stocks insanely cheaper than they used to be,, according to this report from VoXEU & CEPR. As a result, the people’s interest in the stock market accumulated to greater heights
Web Scraping for Data Science
By: ProxyScrapeMay-18-2021
Organizations currently extract enormous volumes of data for analysis, processing, and advanced analysis to identify patterns from those data so stakeholders can draw informed conclusions. As the Data Science field is growing rapidly and has revolutionized so many industries, it is worth getting to know how organizations extract these tons of data. Up to date
Guide to Web Scraping For Competitive Intelligence & Pricing Strategy
By: ProxyScrapeMay-05-2021
One way for your business to have a competitive advantage over your competitors is your ability to gather, analyze, and use information collected on competitors, customers, and other market factors. This process is known as competitive intelligence or corporate analysis. Competitive intelligence is essential for any business to sustain itself in an era of escalating